Up to now my teams have always had a heterogeneous approach to Application Lifecycle Management. In other words, we've used a variety of tools:
For each of the 4 capabilities we've had to plan and execute migration tasks.
For the migration of work from Jira I've been using Solidify's migration tool. It's pretty nifty! It downloads Jira issues into JSON files which are then pushed up into Azure DevOps. As part of the process you specify mappings for issue types, fields and users.
One thing it doesn't cover so well is the migration of Sprints.
In Jira information on Sprints, particularly past Sprints, is opaque. The best place I could find to review them was looking through previous Burn Down reports.
Azure DevOps has a structured approach to Sprints. It expects you to define Iterations at 2 levels: at the project level, then associate them with teams.
The Solidify tool does part of the job – it brings across Jira issues as ADO work items and links them to ADO iterations, but only at the team level. It does not create them at the project level. This means that they are not visible where users would expect to see them: in the Sprint planning view.
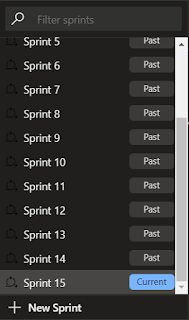
To overcome this I wrote a little utility to pull Sprint information out of Jira and to push it into Azure DevOps at the project level. After running this I could then use the Solidify tool to migrate my issues from Jira to ADO, which completed the team level information and – voila – previous Sprints can be seen from the planning view.
My utility uses the Jira REST API to retrieve Sprint information. To say that Sprints aren't easy to see in the front-end, they're remarkably easy to retrieve via the API. Crucially you need to pass a Board ID for the project for which you want the sprints:
GET https://[yourURL]/jira/rest/agile/1.0/board/[projectBoardId]/sprint
(NB – your Jira username and password need to be encoded and passed in the header)
To make it easy to work with I flipped the returned JSON into a C# object. This was generated using https://json2csharp.com
The class contains a collection of Value objects for each sprint. The properties I need to pass to ADO are: name, startDate and completeDate:
The CreateAdoIteration method is where we pass the information to Azure DevOps to create an Iteration.
POST https://dev.azure.com/[yourOrganisation]/[yourProject]/_apis/wit/classificationnodes/Iterations?api-version=6.0
(NB – your Personal Access Token (PAT) must be encoded and passed in the header)
Again, I used https://json2csharp.com to create a C# Iteration object to be passed as JSON content to the API:
And that's it. I've looped through the sprints returned from Jira and created a project iteration for each of them in Azure DevOps. Easier than I thought!
Happy coding.
- Jira – for tracking work
- Subversion – for source code
- TeamCity – for automated builds and continuous integration
- Octopus Deploy – for "one-click" deployments to dev, test and production environments
For each of the 4 capabilities we've had to plan and execute migration tasks.
For the migration of work from Jira I've been using Solidify's migration tool. It's pretty nifty! It downloads Jira issues into JSON files which are then pushed up into Azure DevOps. As part of the process you specify mappings for issue types, fields and users.
One thing it doesn't cover so well is the migration of Sprints.
In Jira information on Sprints, particularly past Sprints, is opaque. The best place I could find to review them was looking through previous Burn Down reports.
Azure DevOps has a structured approach to Sprints. It expects you to define Iterations at 2 levels: at the project level, then associate them with teams.
The Solidify tool does part of the job – it brings across Jira issues as ADO work items and links them to ADO iterations, but only at the team level. It does not create them at the project level. This means that they are not visible where users would expect to see them: in the Sprint planning view.
To overcome this I wrote a little utility to pull Sprint information out of Jira and to push it into Azure DevOps at the project level. After running this I could then use the Solidify tool to migrate my issues from Jira to ADO, which completed the team level information and – voila – previous Sprints can be seen from the planning view.

My utility uses the Jira REST API to retrieve Sprint information. To say that Sprints aren't easy to see in the front-end, they're remarkably easy to retrieve via the API. Crucially you need to pass a Board ID for the project for which you want the sprints:
GET https://[yourURL]/jira/rest/agile/1.0/board/[projectBoardId]/sprint
(NB – your Jira username and password need to be encoded and passed in the header)
To make it easy to work with I flipped the returned JSON into a C# object. This was generated using https://json2csharp.com
The class contains a collection of Value objects for each sprint. The properties I need to pass to ADO are: name, startDate and completeDate:
foreach (var sprint in sprintInfo.Values) { var startDate = Convert.ToDateTime(sprint.startDate); var endDate = Convert.ToDateTime(sprint.completeDate); CreateAdoIteration(sprint.name, startDate, endDate); }
The CreateAdoIteration method is where we pass the information to Azure DevOps to create an Iteration.
POST https://dev.azure.com/[yourOrganisation]/[yourProject]/_apis/wit/classificationnodes/Iterations?api-version=6.0
(NB – your Personal Access Token (PAT) must be encoded and passed in the header)
Again, I used https://json2csharp.com to create a C# Iteration object to be passed as JSON content to the API:
var iteration = new Iteration { name = sprintName, attributes = new Attributes { startDate = startDate, finishDate = endDate } }; var iterationJson = JsonConvert.SerializeObject(iteration);
And that's it. I've looped through the sprints returned from Jira and created a project iteration for each of them in Azure DevOps. Easier than I thought!
Happy coding.
Comments
Post a Comment